

How Is The Distributed Data Stored In Pandas Dataframe In Spark
Spark has an easy-to-use API for handling structured and unstructured data called Dataframe. Every DataFrame has a blueprint called a Schema. It can contain universal data types string types and integer types and the data types which are specific to spark such every bit struct blazon. Let'south discuss what is Spark DataFrame, its features, and the application of DataFrame.
- What is Spark DataFrame?
- Why DataFrames?
- Features of DataFrames
- Creating DataFrames
- DataFrame Operations
- Applications of DataFrames
- Spark Datasets
- DataFrames vs RDDs vs Datasets
What is Spark DataFrame?
In Spark, DataFrames are the distributed collections of information, organized into rows and columns. Each column in a DataFrame has a name and an associated type. DataFrames are similar to traditional database tables, which are structured and concise. Nosotros can say that DataFrames are relational databases with better optimization techniques.
Spark DataFrames tin be created from various sources, such as Hive tables, log tables, external databases, or the existing RDDs. DataFrames permit the processing of huge amounts of data.
Cheque out this video on Spark Tutorial for beginners:
Spark DataFrame Spark DataFrame
Why DataFrames?
When Apache Spark one.3 was launched, it came with a new API called DataFrames that resolved the limitations of performance and scaling that occur while using RDDs.
When at that place is not much storage infinite in memory or on disk, RDDs practise not function properly as they go exhausted. Besides, Spark RDDs practise not have the concept of schema—the structure of a database that defines its objects. RDDs store both structured and unstructured data together, which is non very efficient.
RDDs cannot alter the organisation in such a way that it runs more efficiently. RDDs exercise not allow us to debug errors during the runtime. They store the data every bit a collection of Java objects.
RDDs use serialization (converting an object into a stream of bytes to allow faster processing) and garbage collection (an automated memory management technique that detects unused objects and frees them from retentivity) techniques. This increases the overhead on the retentiveness of the organization as they are very lengthy.
This was when DataFrames were introduced to overcome the limitations Spark RDDs had. Now, what makes Spark DataFrames so unique? Allow's bank check out the features of Spark DataFrames that brand them so popular.
Read well-nigh Spark from Apache Spark Training and be a master in Apache Spark!
Features of DataFrames
Some of the unique features of DataFrames are:
- Employ of Input Optimization Engine: DataFrames make use of the input optimization engines, e.g., Catalyst Optimizer, to process information efficiently. We can use the same engine for all Python, Java, Scala, and R DataFrame APIs.
- Handling of Structured Data: DataFrames provide a schematic view of data. Here, the data has some pregnant to information technology when it is being stored.
- Custom Memory Direction: In RDDs, the data is stored in memory, whereas DataFrames store data off-heap (outside the main Coffee Heap space, but yet inside RAM), which in turn reduces the garbage drove overload.
- Flexibility: DataFrames, like RDDs, tin support diverse formats of data, such every bit CSV, Cassandra, etc.
- Scalability: DataFrames can exist integrated with various other Large Data tools, and they permit processing megabytes to petabytes of data at once.
Wish to learn Apache Spark in detail? Read this extensive Spark Tutorial!
Get 100% Hike!
Master Most in Demand Skills Now !
Creating DataFrames
There are many ways to create DataFrames. Here are three of the most unremarkably used methods to create DataFrames:
- Creating DataFrames from JSON Files
Now, what are JSON files?
JSON, or JavaScript Object Notation, is a type of file that stores simple information structure objects in the .json format. It is mainly used to transmit data between Web servers. This is how a uncomplicated .json file looks like:
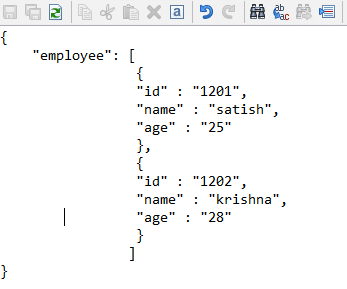
The above JSON is a uncomplicated employee database file that contains two records/rows.
If you lot have more queries related to Big Data Hadoop and Apache Spark, kindly refer to our Big Data Hadoop and Spark Community!
When it comes to Spark, the .json files that are existence loaded are not the typical .json files. Nosotros cannot load a normal JSON file into a DataFrame. The JSON file that we want to load should be in the format given below:
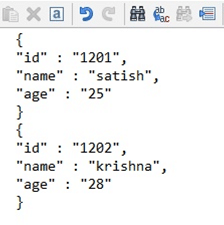
JSON files can be loaded onto DataFrames using the read.JSON function, with the file name we want to upload it.
- Example:
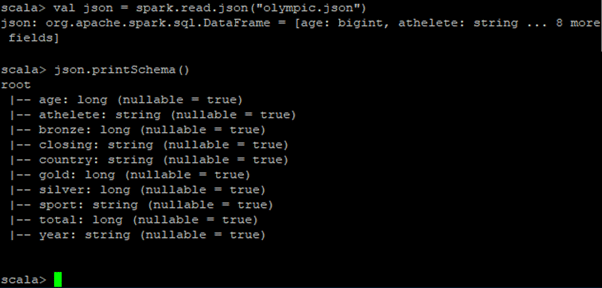
Here, nosotros are loading an Olympic medal count canvas onto a DataFrame. There are ten fields in full. The role printSchema() prints the schema of the DataFrame.
Go familiar with the near asked Spark Interview Questions and Answers to kick-start your career!
- Creating DataFrames from the Existing RDDs
DataFrames tin can too be created from the existing RDDs. Kickoff, we create an RDD and so load that RDD onto a DataFrame using the createDataFrame(Name_of_the_rdd_file) function.
- Example:
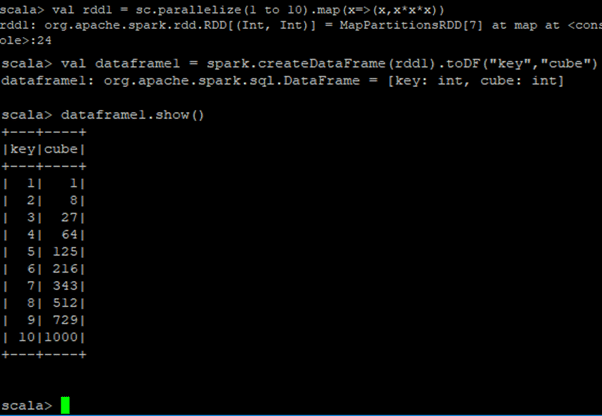
In the below figure, we are creating an RDD first, which contains numbers from i to 10 and their cubes. Then, nosotros will load that RDD onto a DataFrame.
- Creating DataFrames from CSV Files
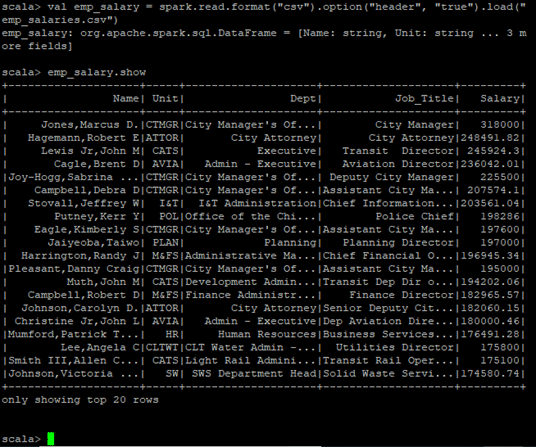
We tin can likewise create DataFrames by loading the .csv files.
Here is an instance of loading a .csv file onto a DataFrame.
DataFrame Operations
For structured Information Manipulation, Spark DataFrame provides a domain-specific language. Let's understand that through an case where the procedure structured data using DataFrames. Let's take an example of a dataset wherein all the details of the employee are stored. Now follow forth with the steps for DataFrame operations:
Read JSON Document
Showtime by reading the JSON Certificate, then generate a DataFrame named (dfs). You tin can use the following command to read the JSON document that is named employee.json. The data nosotros need is shown equally a tabular array with the fields – age, name, and id.
scala> val dfs = sqlContext.read.json("employee.json") The output: Field names will exist taken automatically from the employee.json file.
dfs: org.apache.spark.sql.DataFrame = [age: string, id: string, proper noun: string]
Bear witness the Data
Apply this command if you want to see the data in the DataFrame. The command goes like this:
scala> dfs.show()
The output: You tin can now come across the employee data in a neat tabular format, something like this:
:xviii, took 0.043410 southward +----+------+--------+ |historic period | id | name | +----+------+--------+ | 23 | 1201 | raju | | 25 | 1202 | krishna| | xxx | 1203 | sanjay | | 42 | 1204 | javed | | 37 | 1205 | prithvi | +----+------+--------+
Use Age Filter
You tin now use the following commands to detect out the employees whose age is below 3p (age<xxx).
scala> dfs.filter (dfs("age") <30).bear witness() The Output:
:22, took 0.078670 s +----+------+--------+ |age | id | proper noun | +----+------+--------+ | 23 | 1201 | raju | | 25 | 1202 | krishna| +----+------+--------+
Applications of DataFrame
Spark DataFrames are used in Advanced Analytics and Machine Learning. Data Scientists are using these DataFrames for increasingly sophisticated techniques to become their job done. DataFrames could exist used directly in MLlib's ML pipeline API. Added to that, several different programs tin run complex user functions on DataFrames. These advanced analytics tasks could be specified using ML Pipeline API in MLlib.
Spark Datasets
Datasets are an extension of the DataFrame APIs in Spark. In addition to the features of DataFrames and RDDs, datasets provide various other functionalities.
They provide an object-oriented programming interface, which includes the concepts of classes and objects.
Datasets were introduced when Spark 1.six was released. They provide the convenience of RDDs, the static typing of Scala, and the optimization features of DataFrames.
Datasets are a collection of Java Virtual Machine (JVM) objects that use Spark's Catalyst Optimizer to provide efficient processing.
If you want to learn about Kafka Introduction, refer to this insightful Blog!
DataFrames vs RDDs vs Datasets
| Ground of Difference | Spark RDD | Spark DataFrame | Spark Dataset |
| What is it? | A low-level API | A high-level abstraction | A combination of both RDDs and DataFrames |
| Input Optimization Engine | Cannot brand use of input optimization engines | Uses input optimization engines to generate logical queries | Uses Catalyst Optimizer for input optimization, as DataFrames practise |
| Data Representation | Distributed across multiple nodes of a cluster | A collection of rows and named columns | An extension of DataFrames, providing the functionalities of both RDDs and DataFrames |
| Do good | A simple API | Gives a schema for the distributed information | Improves memory usage |
| Immutability and Interoperability | Tracks information lineage data to recover the lost information | Once transformed into a DataFrame, not possible to get the domain object | Can regenerate RDDs |
| Performance Limitation | Java Serialization and Garbage Drove overheads | Offers huge performance comeback over RDDs | Operations are performed on serialized data to improve performance |
Learn why should you lot choose DataFrames over RDDs in Apache Spark!

Conclusion
Though a few limitations be and Datasets take evolved lately, DataFrames are nonetheless popular in the field of technology. Since they are the extension of RDDs with better levels of abstractions, they are helpful in Advanced Analytics and Machine Learning as they tin can directly access MLlib'southward Machine Learning Pipeline API. Moreover, developers tin can execute circuitous programs using DataFrames easily. Hence, DataFrames are even so used past lots of users because of their incredibly fast processing and ease of employ.
Intellipaat provides the most comprehensive Big Data and Spark Course in New York to fast-track your career!

How Is The Distributed Data Stored In Pandas Dataframe In Spark,
Source: https://intellipaat.com/blog/tutorial/spark-tutorial/spark-dataframe/
Posted by: gonzalesnowent.blogspot.com
0 Response to "How Is The Distributed Data Stored In Pandas Dataframe In Spark"
Post a Comment